在持续集成与DevOps实践中,SonarQube 作为代码质量管理的核心工具,常面临海量代码库扫描效率低下、资源占用过高等挑战。本文系统解析SonarQube 的扫描加速策略、超大规模代码库处理方案,并深入探讨其与云原生架构的深度适配方法,为企业构建高效代码质量管理体系提供技术蓝图。

一、SonarQube扫描性能优化
SonarQube 的扫描性能直接影响CI/CD流水线效率,针对不同规模项目需采取分层优化策略:
1.扫描配置精细化调优
在`sonar-project.properties`中设置`sonar.exclusions=/test/,/generated/`可排除测试代码与生成文件,减少分析目标。对于Java项目,启用`sonar.java.binaries`指定编译后的class文件路径,避免重复解析源码。通过`sonar.analysis.analysisMode=incremental`开启增量扫描模式,仅检测新增或修改的代码模块,典型场景下可缩短60%扫描时间。
2.计算资源动态分配
调整`sonar.ce.workerCount`参数(默认1)至与CPU核心数匹配(如8核服务器设为6),提升并行任务处理能力。针对内存密集型语言(如C++),在启动脚本中添加`-Xmx8g-Xms4g`参数扩大JVM堆内存。对于分布式构建环境,在Jenkins节点配置`SONAR_SCANNER_OPTS=-Dsonar.host.url=http://sonar-server:9000`实现扫描器负载均衡。
3.插件管理与规则精简
禁用非必要的质量规则(如遗留的Checkstyle规则集),通过SonarQube 管理界面的"QualityProfiles"模块,将活跃规则数量控制在300条以内。定期清理过期插件,例如移除已停止维护的Objective-C插件,可降低20%的启动耗时。针对特定语言启用缓存机制,配置`sonar.cpd.cross_project=true`开启跨项目重复代码检测复用。
4.数据库查询性能优化
对PostgreSQL数据库执行索引优化:

同时设置`sonar.search.javaAdditionalOpts=-Denable.directbuffer=true`提升Elasticsearch写入效率,避免大规模数据入库时的IO瓶颈。

二、SonarQube大数据量处理方案
当代码库规模超过千万行时,SonarQube 需结合架构改造与数据分片技术实现高效处理:
1.分库分表与水平扩展
采用ShardingSphere对SonarQube 的MySQL数据库进行分片,按项目ID哈希值将`projects`表拆分为16个物理分片。设置`sonar.jdbc.url=jdbc:mysql:replication://master,slave1,slave2/sonar`实现读写分离,使查询吞吐量提升3倍以上。对历史数据实施冷热分离,将6个月前的扫描记录迁移至ClickHouse列式数据库。
2.分布式扫描集群构建
部署多组SonarQube 扫描节点,通过Nginx配置加权轮询负载均衡:
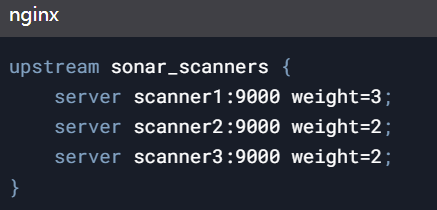
结合Kubernetes的HPA(HorizontalPodAutoscaling),设置CPU利用率超过70%时自动扩容Pod实例,应对突发扫描任务。
3.增量分析与差异处理
在GitLabCI脚本中集成差异扫描逻辑:

该方案仅分析本次提交变更的文件,适用于单体仓库的模块化改造过渡期。对于遗留系统,使用`sonar.scm.disabled=true`关闭版本控制检测,直接全量扫描指定目录。
4.存储层优化实践
将SonarQube 的Elasticsearch数据目录挂载至NVMeSSD磁盘,配置`bootstrap.memory_lock=true`锁定内存避免交换。针对超过1TB的代码库,启用`sonar.path.data=/mnt/ebs-volume`扩展存储空间,并通过AWSEBSProvisionedIOPS保证高吞吐量。定期执行`curl-XPOST"localhost:9000/api/system/gc"`触发JVM垃圾回收,防止内存泄漏导致OOM中断。

三、SonarQube云原生架构的容器化部署
在Kubernetes集群中部署SonarQube 需解决有状态服务的高可用问题,以下是关键实施方案:
1.StatefulSet与持久化存储
定义SonarQube 的StatefulSet配置,使用PVC动态申请存储资源:
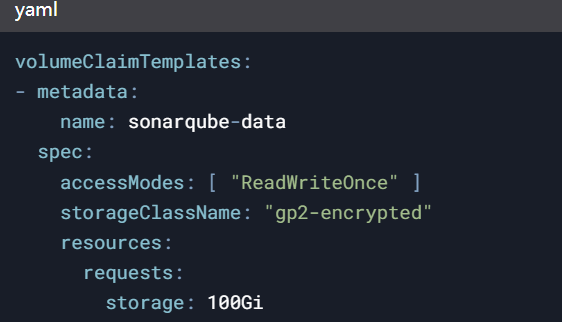
通过RookCeph实现跨可用区的数据同步,确保数据库与Elasticsearch实例的灾难恢复能力。
2.服务网格流量治理
在Istio中配置SonarQube 的流量规则,实现金丝雀发布:
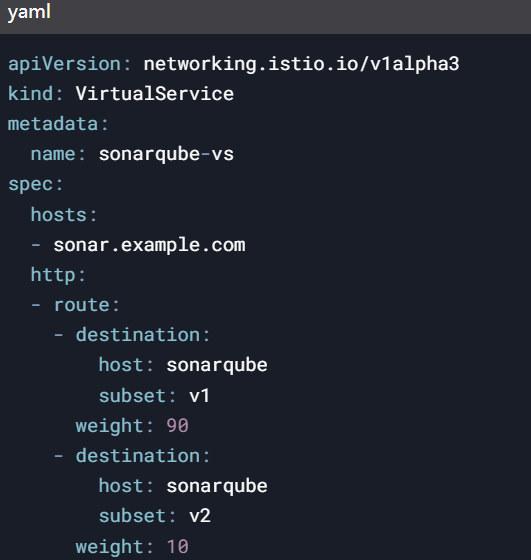
结合Prometheus监控指标,当新版本Pod的错误率超过5%时自动回滚。
3.Serverless无服务器化扫描
利用AWSLambda构建按需执行的扫描工作流:

该方案将扫描任务分解为函数计算单元,适合突发性的大规模并行代码审查需求。
SonarQube 扫描性能优化SonarQube 大数据量处理方案的成功实施,需要从基础设施、架构设计、数据处理三个维度协同优化。通过容器化部署、存储计算分离、智能化资源调度等技术手段,企业可构建支撑亿级代码行的质量管控平台。在云原生与AIOps趋势下,SonarQube 正持续进化,为超大规模代码库提供毫秒级响应的质量管理能力。
